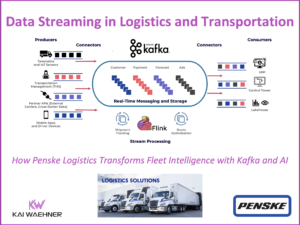
168极速赛车官网直播结果 最新168赛车官方记录 官网历史数据查询 How Penske Logistics Transforms Fleet Intelligence with Data Streaming and AI
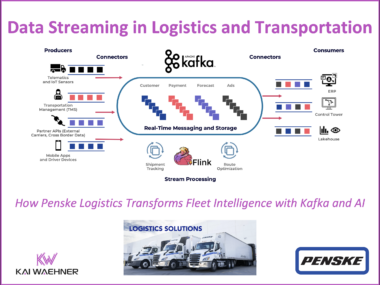
Real-time visibility has become essential in logistics. As supply chains grow more complex, providers must shift from delayed, batch-based systems to event-driven architectures. Data Streaming technologies like Apache Kafka and Apache Flink enable this shift by allowing continuous processing of data from telematics, inventory systems, and customer interactions. Penske Logistics is leading the way—using Confluent’s platform to stream and process 190 million IoT messages daily. This powers predictive maintenance, faster roadside assistance, and higher fleet uptime. The result: smarter operations, improved service, and a scalable foundation for the future of logistics.