Kafka was not built for large messages. Period. Nevertheless, more and more projects send and process 1Mb, 10Mb, and even much bigger files and other large payloads via Kafka. One reason is that Kafka was designed for large volume/throughput – which is required for large messages. This blog post covers the use cases, architectures, and trade-offs for handling large messages with Kafka.
Use Cases for Large (Kafka) Message Payloads
Various use cases for large message payloads exist: Image recognition, video analytics, audio analytics, and file processing are widespread examples.
Image Recognition and Video Analytics
Image recognition and video analytics (also known as computer vision) is probably the number one use case. Many examples require the analysis of videos in real-time, including:
- Security and surveillance (access control, intrusion detection, motion detection)
- Transport monitoring system (vehicle traffic detection, incidence detection, pedestrian monitoring)
- Healthcare (health status monitoring, telemedicine, surgical video analysis)
- Manufacturing (machine vision for quality assurance, augmented support and training)
The usage of image and video processing via concepts such as Computer Vision (e.g., OpenCV) or Deep Learning / Neural Networks (e.g., TensorFlow) reduces time, cost, and human effort, plus this makes industries more secure, reliable, and consistent.
Audio Analytics
Audio analytics is an interesting use case, coming up more and more:
- In conjunction with video analytics: See the use cases above. Often video and audio need to be processed together.
- Consumer IoT (CIoT): Alerting, informing, advising people, e.g., using Audio Analytic.
- Industrial IoT (IIoT): Machine diagnostics and predictive maintenance using advanced sound analysis, e.g., using Neuron Soundware
- Natural Language Processing (NLP): Chatbots and other modern systems use text and speech translation, e.g., using the fully-managed services from the major cloud providers
Big Data File Processing
Last but not least, the processing of big files received in batch-mode will not go away any time soon. But big files can be incorporated into a modern event streaming workflow for decoupling/separation of concerns, connectivity to various sinks. And it allows data processing in real-time and batch simultaneously.
Legacy systems will provide data sources like big CSV or proprietary files or snapshots/exports from databases that need to be integrated. Data processing includes streaming applications (such as Kafka Streams, ksqlDB, or Apache Flink) to continuously process, correlate, and analyze events from different data sources. Data sources such as Hadoop or Spark processed incoming data in batch mode (e.g., map/reduce, shuffling). Other data sources such as data warehouse (e.g., Snowflake) or text search (e.g., Elasticsearch) ingest data in near-real-time.
What Kafka is NOT
After exploring use cases for large message payloads, let’s clarify what Kafka is not:
Kafka is usually not the right technology to store and process large files (images, videos, proprietary files, etc.) as a whole. Products were built specifically for these use cases.
For instance, a Content Delivery Network (CDN) such as Akamai, Limelight Networks, or Amazon CloudFront distribute video streams and other software downloads across the globe. Or “big file editing and processing” (like a video processing tool). Or video editing tools from Adobe, Autodesk, Camtasia, and many other vendors are used to structure and present all video information, including films and television shows, video advertisements, and video essays.
Let’s take a look at one example that combines Kafka and these other tools:
Netflix processes over 6 Petabytes per day with Kafka. However, this is “just” for message orchestration, coordination, data integration, data preprocessing, ingestion into data lakes, building stateless and stateful business applications, and other use cases. But Kafka is not used to sharing and storing all the shows and movies you watch on your TV or tablet. A Content Delivery Network (CDN) like Akamai is used in conjunction with other tools and products to provide you the excellent video streaming experience you know.
Okay, Kafka is not the right tool to store and process large files as a whole, like a CDN or video editing tool. Why, when, and how should you handle large message payloads with Kafka then? And what is a “large message” in Kafka terms?
Features and Limitations of using Kafka for Large Messages
Originally, Kafka was not built for processing large messages and files. This does not mean that you cannot do it!
Kafka limits the max size of messages. The default value of the broker configuration’ ‘ message.max.bytes’ is 1MB.
Why does Kafka limit the message size by default?
- Different sizing, configuration, and tuning required for large message handling compared to a mission-critical real-time cluster with low latency.
- Large messages increase the memory pressure on the broker JVM.
- Large messages are expensive to handle and could slow down the brokers.
- A reasonable message size limit can meet the requirements of most use cases.
- Good workarounds exist if you need to handle large messages.
- Most cloud offerings don’t allow large messages.
There are noticeable performance impacts from increasing the allowable message size.
Hence, understand all alternatives discussed below before sending messages >1Mb through your Kafka cluster. Depending on your SLAs for uptime and latency, a separate Kafka cluster should be considered for processing large messages.
Having said this, I have seen customers processing messages far bigger than 10Mb with Kafka. It is valid to evaluate Kafka for processing large messages instead of using another tool for that (often in conjunction with Kafka).
LinkedIn talked a long time ago about the pros and cons of two different approaches: Using ‘Kafka only’ vs. ‘Kafka in conjunction with another data storage’. Especially outside the public cloud, most enterprises cannot simply use an S3 object store for big data. Therefore, the question comes up if one system (Kafka) is good enough, or if you should invest in two systems (Kafka and external storage).
Let’s take a look at the trade-offs for using Kafka for large messages.
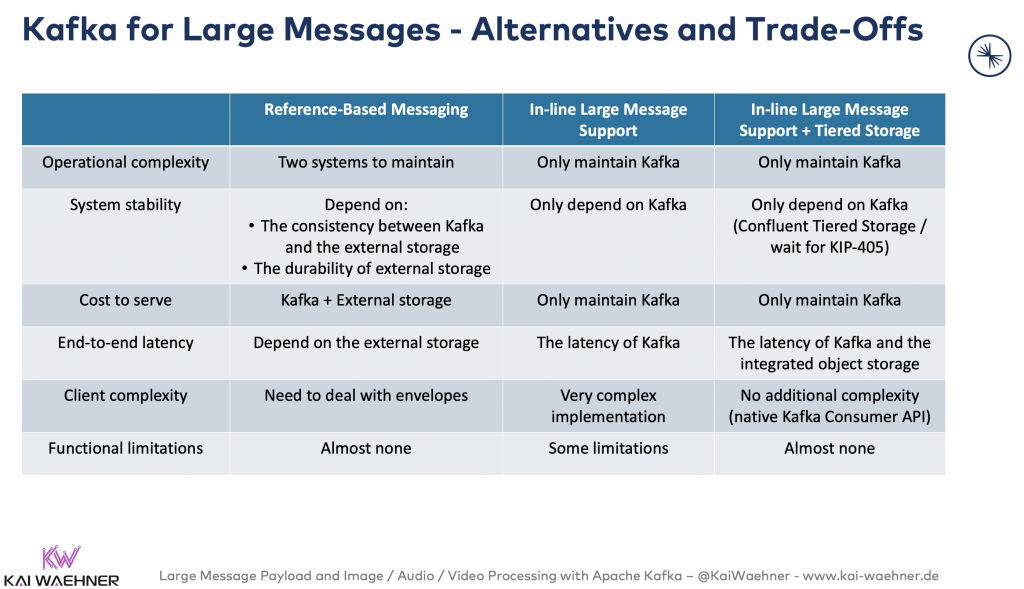
Kafka for Large Messages – Alternatives and Trade-Offs
There is no single best solution. The decision on how to handle large messages with Kafka depends on your use cases, SLAs, and already existing infrastructure.
The following three available alternatives exist to handle large messages with Kafka:
- Reference-based messaging in Kafka and external storage
- In-line large message support in Kafka without external storage
- In-line large message support and tiered storage in Kafka
Here are the characteristics and pros/cons of each approach (this is an extension from a LinkedIn presentation in 2016):
Also, don’t underestimate the power of compression for large messages. Some big files like CSV or XML can reduce its size significantly just by setting the compression parameter to use GZIP, Snappy, or LZ4.
Even a 1GB file could be sent via Kafka, but this is undoubtedly not what Kafka was designed for. In both the client and the broker, a 1GB chunk of memory will need to be allocated in JVM for every 1GB message. Hence, in most cases, for really large files, it is better to externalize them into an object store and use Kafka just for the metadata.
You need to define what is ‘a large message’ by yourself and when to use which of the design patterns discussed in this blog post. That’s why I am writing this up here… 🙂
The following sections explore these alternatives in more detail. Before we start, let’s explain the general concept of Tiered Storage for Kafka mentioned in the above table. Many readers might not be aware of this yet.
Tiered Storage for Kafka
Kafka data is mostly consumed in a streaming fashion using tail reads. Tail reads leverage OS’s page cache to serve the data instead of disk reads. Older data is typically read from the disk for backfill or failure recovery purposes and is infrequent.
In the tiered storage approach, the Kafka cluster is configured with two tiers of storage – local and remote. Local tier is the same as the current Kafka that uses the local disks on the Kafka brokers to store the log segments. The new remote tier uses an external storage system such as AWS S3, GCS, or MinIO to store the completed log segments. Two separate retention periods are defined corresponding to each of the tiers.
With remote tier enabled, the retention period for the local tier can be significantly reduced from days to few hours. The retention period for remote tier can be much longer, months, or even years.
Tiered Storage for Kafka allows scaling storage independent of memory and CPUs in a Kafka cluster, enabling Kafka to be a long-term storage solution. This also reduces the amount of data stored locally on Kafka brokers and hence the amount of data that needs to be copied during recovery and rebalancing.
The consumer API does not change at all. Kafka applications consume data as before. They don’t even know if Tiered Storage is used under the hood.
Confluent Tiered Storage
Confluent Tiered Storage is available today in Confluent Platform and used under the hood in Confluent Cloud:
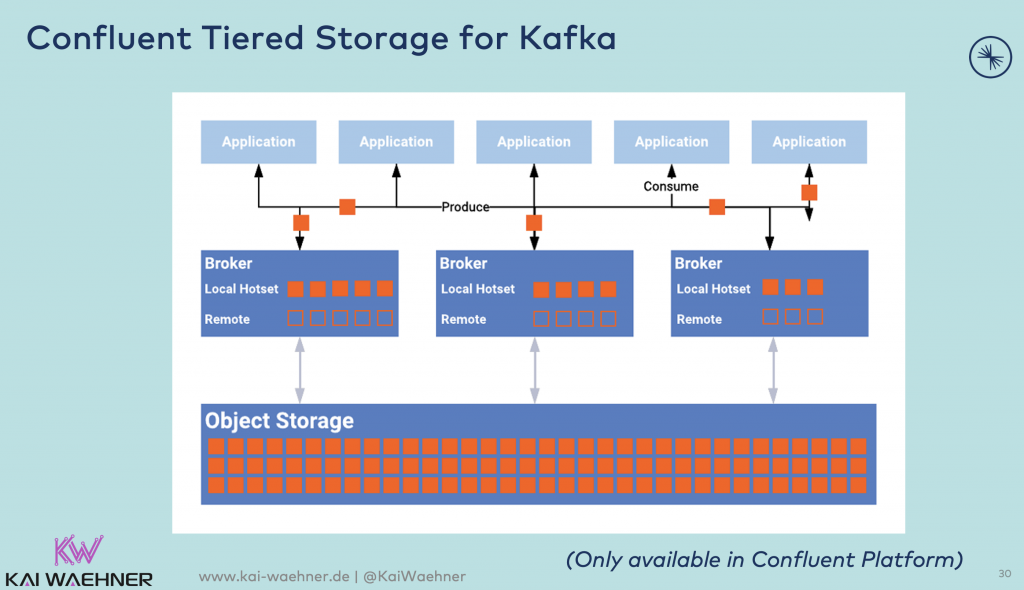
From an infrastructure perspective, Confluent Tiered Storage required an external (object) storage like AWS S3, GCS, or MinIO. But from operations and development perspective, the complexity of end-to-end communication and separation of messages and files is provided out-of-the-box under the hood.
KIP-405 – Add Tiered Storage to Kafka
KIP-405 – Add Tiered Storage Support to Kafka is also in the works. Confluent is actively working on this with the open-source community. Uber is leading this initiative.
Kafka + Tiered Storage is an exciting option (in some use cases) for handling large messages. It provides a single infrastructure to the operator, but also cost savings and better elasticity.
We now understand the technical feasibility of handling large message payloads with Kafka. Let’s now discuss the different use cases and architectures in more detail.
Use Cases and Architectures using Kafka for Large Messages
The processing of the content of your large message payload depends on the technical use case. Do you want to
- Send an image to analyze or enhance it?
- Stream a video to a remote consumer application?
- Analyze audio noise in real-time?
- Process a structured (i.e., splittable) file line-by-line?
- Send an unstructured (i.e., non-splittable) file to a consumer tool to process it?
I cover a few use cases for handling large messages:
- Manufacturing: Quality assurance in production lines deployed at the edge in the factory
- Retailing: Augmented reality for better customer experience and cross/up-selling
- Pharma and Life Sciences: Image processing and machine learning for drug discovery
- Public sector: Security and surveillance
- Media: Content delivery of large video files
- Banking: Attachments in a chat application for customer service
The following sections explore these use cases with different architectural approaches to process large message payloads with Apache Kafka to discuss their pros and cons:
- Kafka-native payload processing
- Chunk and re-assemble
- Metadata in Kafka and linking to external storage
- Externalizing large payloads on-the-fly
Kafka for Large Message Payloads – Image Processing
Computer vision and image recognition are used in many industries, including automotive, manufacturing, healthcare, retailing, and innovative “silicon valley use cases”. Image processing includes tools such as OpenCV but also technologies implementing deep learning algorithms such as Convolutional Neural Networks (CNN).
Let’s take a look at a few examples from different industries.
Kafka-native Image Processing for Machine Vision in Manufacturing
Machine Vision is the technology and methods used to provide imaging-based automatic inspection and analysis for such applications as automated inspection, process control, and robot guidance, usually in industry.
A Kafka-native machine vision implementation sends images from cameras to Kafka. Preprocessing adds metadata and correlation it with data from other backend systems. The message is then consumed by one or more applications:
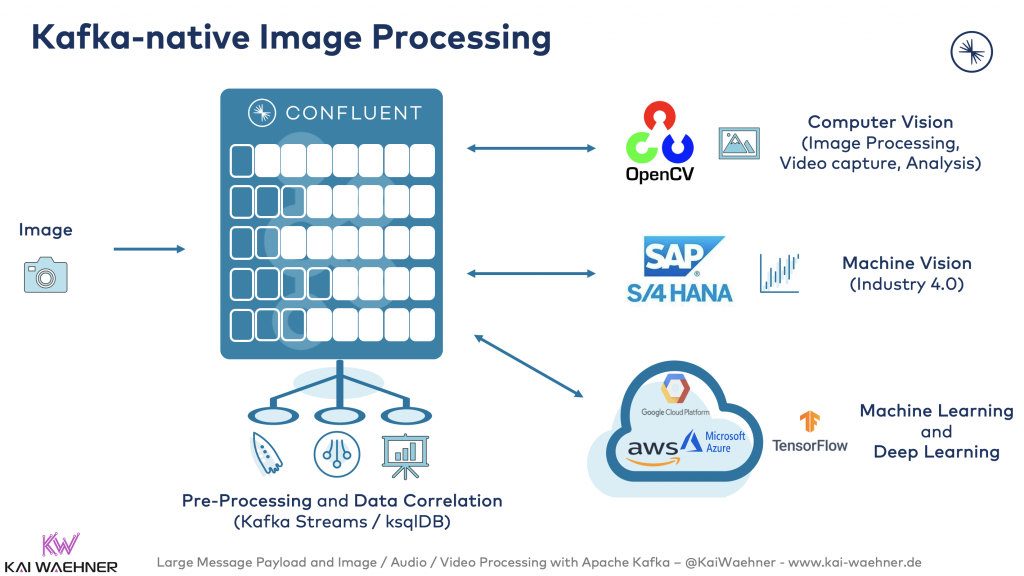
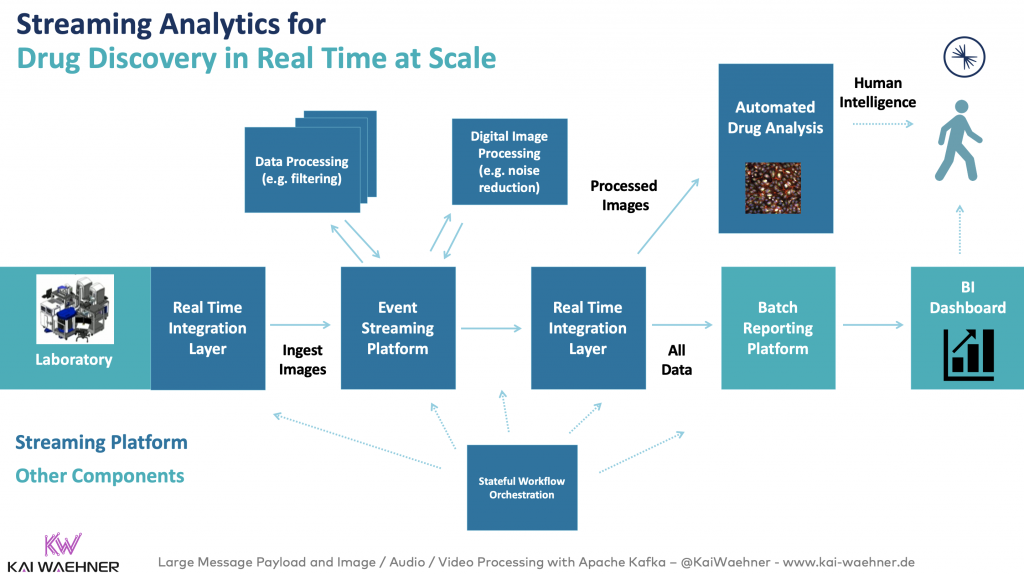
Image processing and machine learning for drug discovery in Pharma and Life Sciences
“On average, it takes at least ten years for a new medicine to complete the journey from initial discovery to the marketplace” said PhRMA.
Here is one example where event streaming at scale in real-time speeds up this process significantly.
Recursion had several technical challenges. Their drug discovery process was manual and slow, bursty batch mode, not scalable:
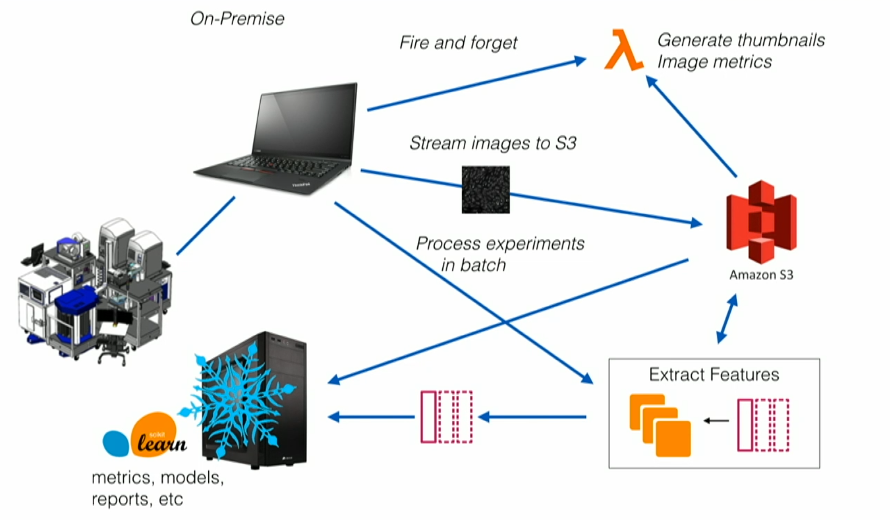
To solve these challenges, Recursion leveraged Kafka and its ecosystem to built a massively parallel system that combines experimental biology, artificial intelligence, automation, and real-time event streaming to accelerate drug discovery:
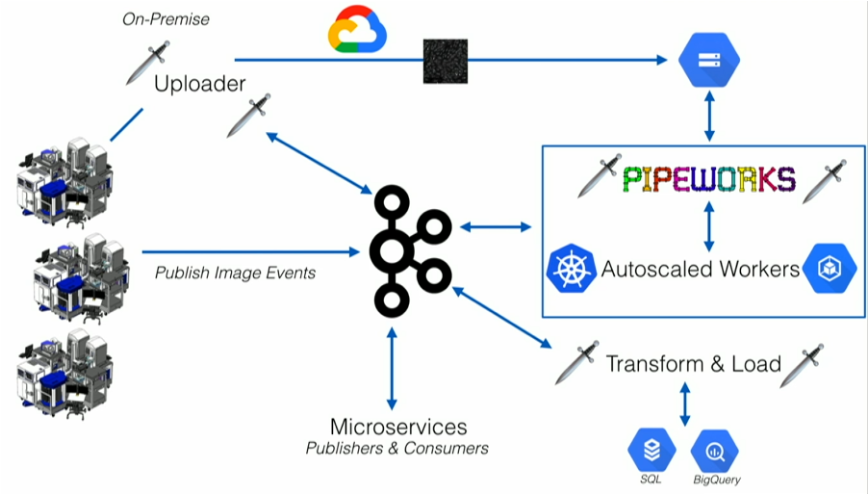
Check out Recusion’s Kafka Summit talk to learn more details.
I see plenty of customers in various industries implementing scalable real-time machine learning infrastructures with the Kafka ecosystem. Related to the above use case, I explored more details in the blog post “Apache Kafka and Event Streaming in Pharma and Life Sciences“. The following shows a potential ML infrastructure:
Kafka-native Image Recognition for Augmented Reality in Retailing
Augmented reality (AR) is an interactive experience of a real-world environment where the objects that reside in the real world are enhanced by computer-generated perceptual information. AR applications are usually built with engines such as Unity or Unreal. Use cases exist in various industries. Industry 4.0 is the most present one today. But other industries start building fascinating applications. Just think about Pokemon Go from Nintendo for your smartphone.
The following shows an example of AR in the telco industry for providing an innovative retailing service. The customer makes a picture of his home, sends the picture to an OTT service of the Telco provider, and receives the enhanced picture (e.g, with a new couch to buy for your home):
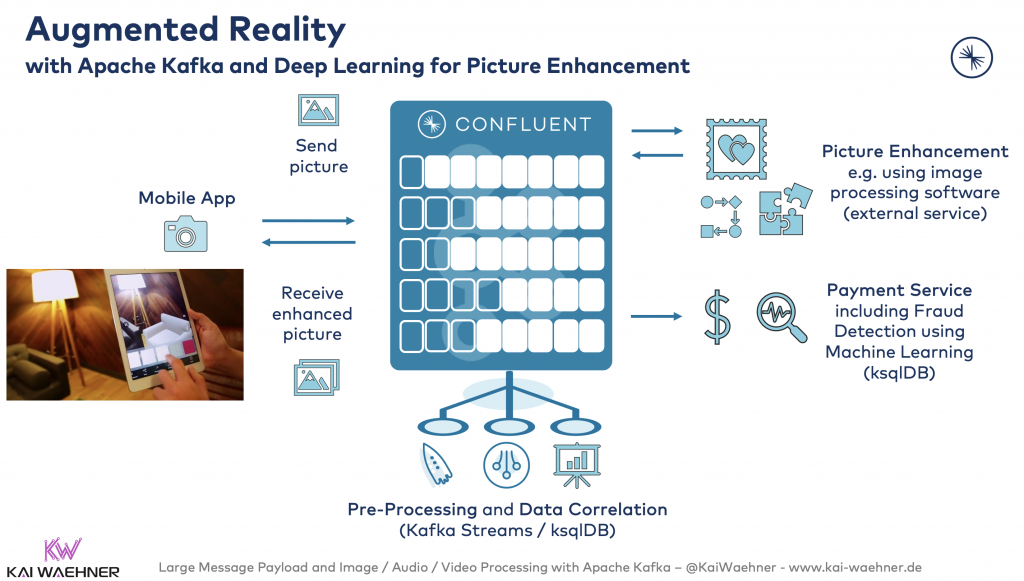
Kafka is used for orchestration, integration with backend services, and sending the original and enhanced image between the smartphone and the OTT Telco service.
Machine Vision at the Edge in Industrial IoT (IIoT) with Confluent and Hivecell
Kafka comes up at the edge more and more. Here is an example of machine vision at the edge with Kafka in Industrial IoT (IIoT) / Industry 4.0 (I4):
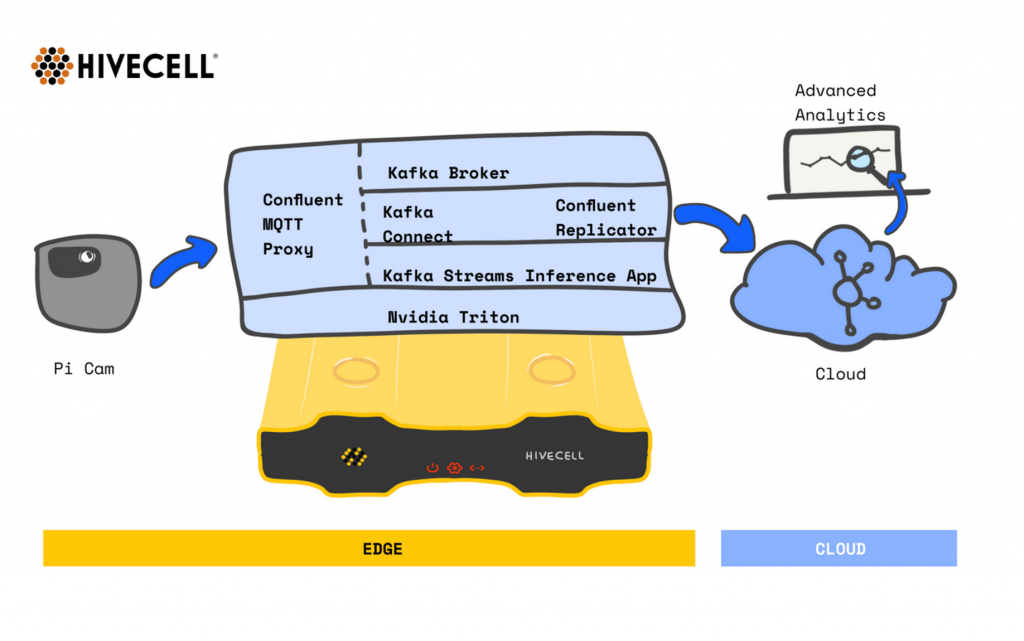
A Hivecell node is equipped with
- Confluent MQTT Proxy: Integration with the cameras
- Kafka Broker and ZooKeeper: Event streaming platform
- Kafka Streams: Data processing, such as filtering, transformations, aggregations, etc.
- Nvidia’s Triton Inference server: Image recognition using trained analytic models
- Kafka Connect and Confluent Replicator: Replication of the machine vision results to the cloud
Video Streaming with Apache Kafka
Streaming media is the process of delivering and obtaining media. Data is continuously received by and presented to one or more consumers while being delivered by a provider. Buffering the split up data packages of videos on the consumer side ensures a continuous flow.
The implementation of video streaming with Kafka-native technologies is pretty straightforward:
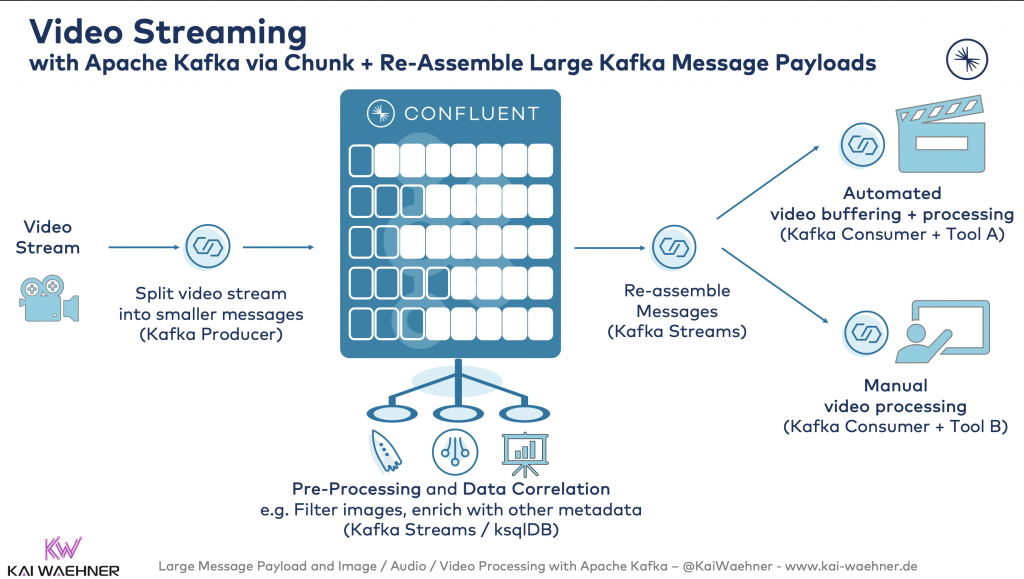
This architecture leverages the Composed Message Processor Enterprise Integration Pattern (EIP):
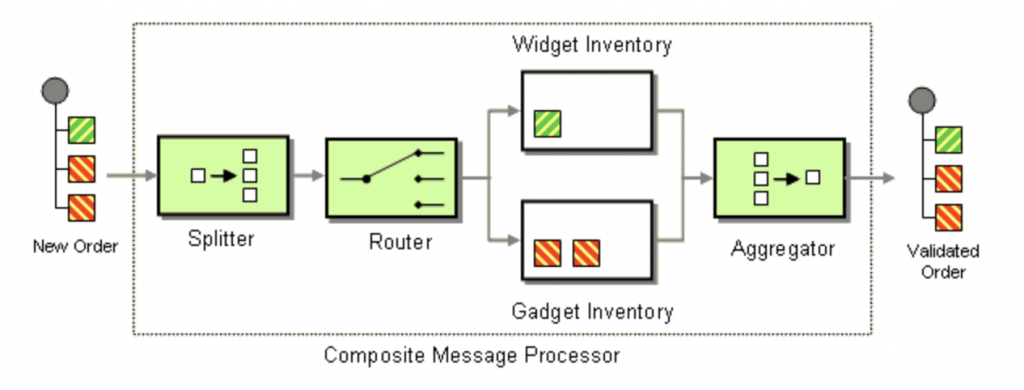
The use case is even more straightforward, as we don’t need a content-based router in our case. We just combine the Splitter and Aggregator EIPs.
The blog post “Building a distributed multi-video processing pipeline with Python and Confluent Kafka” shows a great demo of processing a stream of video frames with Kafka.
Split and aggregate video streams for security and surveillance in the public sector
The following shows a use case for video streaming with Kafka for security and surveillance:
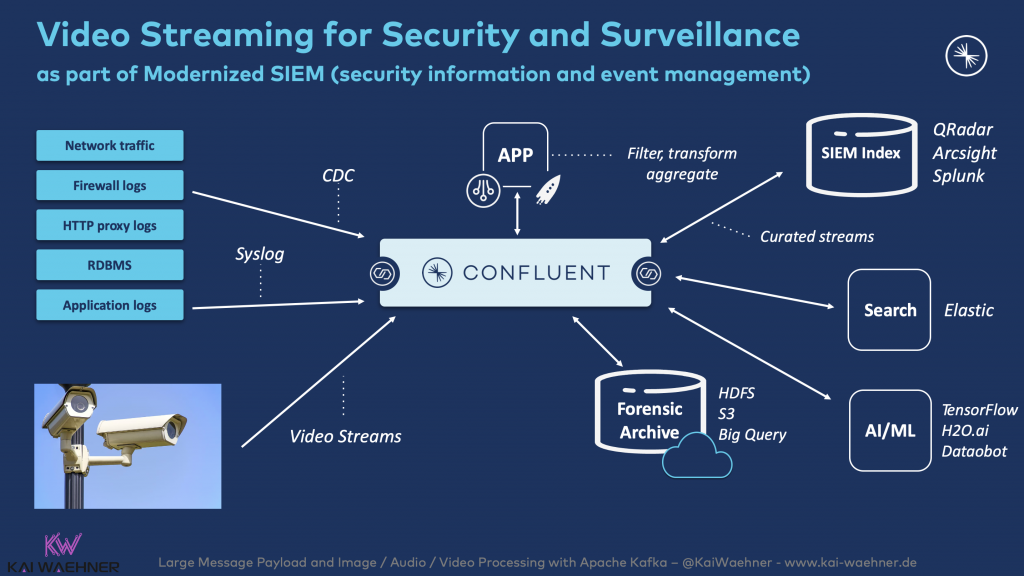
In this case, video streaming is part of a modernized SIEM (security information and event management). Audio streaming works in a very similar way. Hence, I will not cover it separately.
A smart city is another example where video, image, and audio processing with Kafka come into play.
Kafka for Large Message Payloads – Big Data Files (CSV, XML, Video, Proprietary)
Up above, we have seen examples for processing specific large messages: Images, video, audio. In many use cases, other kinds of files need to be processed. Large files include:
- Structured data, e.g., big CSV or XML files
- Unstructured data, e.g., complete videos (not continuous video streaming) or other binary files such as an analytic model
Big Aggregated Files from Offline Devices in IoT
Big CSV, XML or JSON files are even normality in modern real-time event-based architectures. Connected cars are one example. In theory, every event is sent in real-time (check out the Audi keynote at Kafka Summit for this use case). In practice, cars (or other IoT devices) are offline regularly. Many firmware implementations then send the data as a big aggregated file as Tesla described in a Confluent blog:
“One of the unique challenges with device data streams, as opposed to web server log data streams, is that it is normal for devices to become disconnected for a long while – easily months – and to then send a huge amount of data as they come back online. Depending on how your device firmware is written, this could mean many, many small messages (which can be wasteful for storage and bandwidth considerations), or, more likely, the backlog of small messages batched together as a couple of large messages. If we were to just blindly write these into the same Kafka topics that we were planning to use for regular ingest, it could easily overwhelm our cluster.”
Similarly to the video streaming use case discussed above, Enterprise Integration Patterns such as Splitter, Router, and Aggregator are perfect for this scenario. Download the big file at once, split it up, process event by event, and if necessary, route or aggregate the events again.
Claim Check Enterprise Integration Pattern for non-splittable Large Messages
As I said before, Kafka is not the right technology to store big files. Specific tools were built for this, including object stores such as AWS S3 or MinIO.
The Claim Check EIP is the perfect solution for this problem:
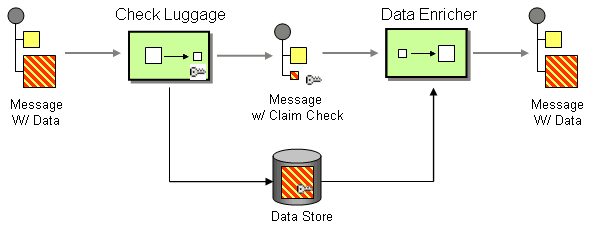
Metadata in Kafka and linking to external storage for content delivery of large video files in the media industry
Many large video files are produced in the media industry. Specific storage and video editing tools are used. Kafka does not send these big files. But it controls the orchestration in a flexible, decoupled real-time architecture:
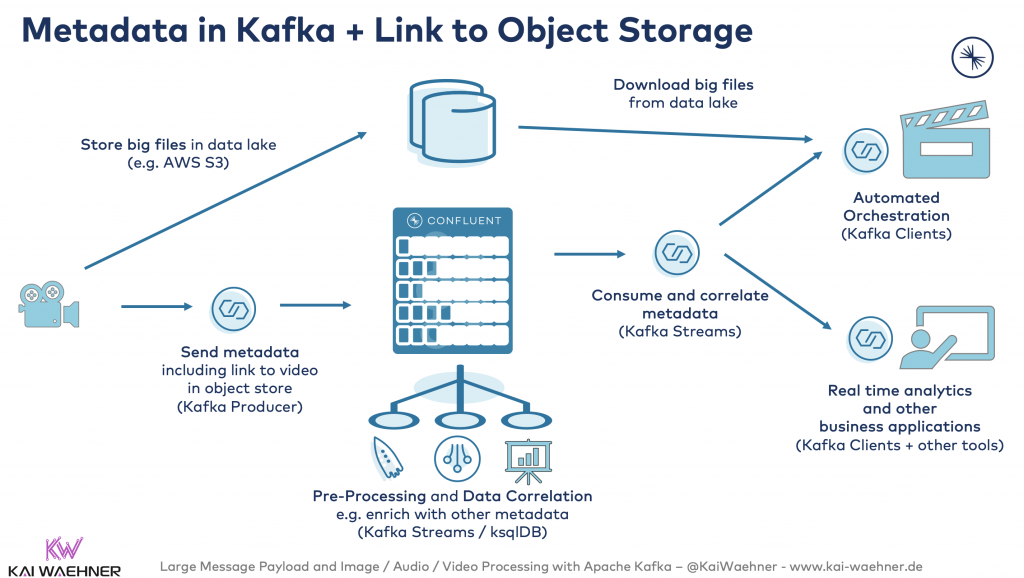
Externalizing large payloads on-the-fly for legacy integration from proprietary systems in Financial Services
Big files have to be processed in many industries. In financial services, I saw several use cases where large proprietary files have to be shared between different legacy applications.
Similar to the Claim Check EIP used above, you can also leverage Kafka Connect and its Single Message Transformations (SMT) feature:
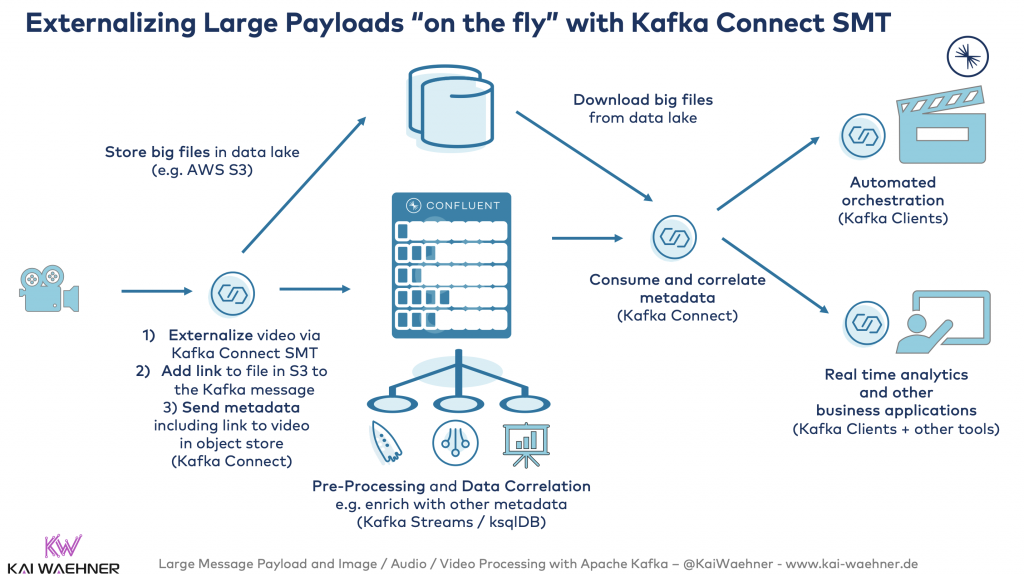
Here is a detailed example of processing large XML files with Kafka Connect and the open-source File Pulse connector: “Streaming data into Kafka – Loading XML file“.
Natural Language Processing (NLP) using Kafka and Machine Learning for Large Text Files
Machine Learning and Kafka are a perfect fit. I covered this topic in many articles and talks in the past. Just google or start with this blog post to get an idea about this approach: “Using Apache Kafka to Drive Cutting-Edge Machine Learning“.
Natural Language Processing (NLP) using Kafka and machine learning for large text files is a great example. “Continuous NLP Pipelines with Python, Java, and Apache Kafka” shows how to implement the above design pattern using Kafka Streams, Kafka Connect, and an S3 Serializer / Deserializer.
I really like this example because it also solves the impedance mismatch between the data scientist (who loves Python) and the production engineer (who loves Java). “Machine Learning with Python, Jupyter, KSQL and TensorFlow” explores this challenge in more detail.
Large Messages in a Chat Application for Customer Service in Banking
You just learned how to handle large files with Kafka by externalizing them into an object store and only sending the metadata via Kafka. In some use cases, this is too much effort or cost. Sending large files directly via Kafka is possible and sometimes easier to implement. The architecture is much simpler and more cost-effective.
I already discussed the trade-offs above. But here is an excellent use case of sending large files natively with Kafka: Attachments in a chat application for customer service.
An example of a financial firm using Kafka for a chat system is Goldman Sachs. They led the development of Symphony, an industry initiative to build a cloud-based platform for instant communication and content sharing that securely connects market participants. Symphony is based on an open-source business model that is cost-effective, extensible, and customizable to suit end-user needs. Many other FinServ companies invested into Symphony, including Bank of America, BNY Mellon, BlackRock, Citadel, Citi, Credit Suisse, Deutsche Bank, Goldman Sachs, HSBC, Jefferies, JPMorgan, Maverick, Morgan Stanley, Nomura, and Wells Fargo.
Kafka is a perfect fit for chat applications. The broker storage and decoupling are perfect for multi-platform and multi-technology infrastructure. Offline capabilities and consuming old messages are built into Kafka, too. Here is an example from a chat platform in the gaming industry:
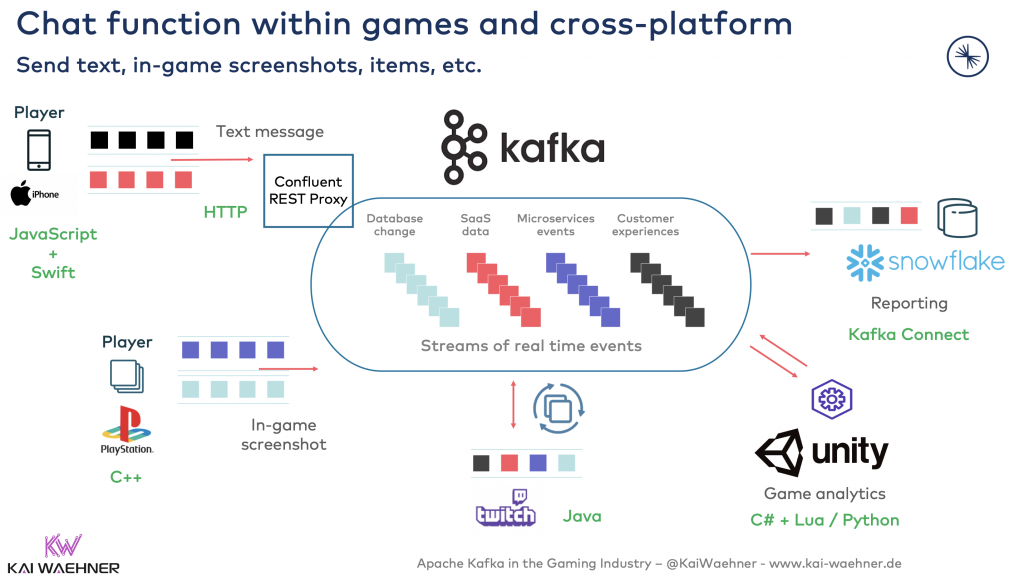
Attachments like files, images, or any other binary content can be part of this implementation. Different architectures are possible. For instance, you could use dedicated Kafka Topics for handling large messages. Or you just put them into your’ ‘ chat message’ event. With Confluent Schema Registry, the schema could have an attribute ‘attachment’. Or you externalize the attachment using the Claim Check EIP discussed above.
Kafka-native handling of large messages has its use cases!
As you learned in this post, plenty of use cases exist for handling large messages files with Apache Kafka and its ecosystem. Kafka was built for large volume/throughput – which is required for large messages. ‘Scaling Apache Kafka to 10+ GB Per Second in Confluent Cloud‘ is an impressive example.
However, not all large messages should be processed with Kafka. Often you should use the right storage system and just leverage Kafka for the orchestration. Know the different design patterns and choose the right technology for each problem.
A common scenario for Kafka-native processing of large messages is at the edge where other data storages are often not available or would increase the cost and complexity for provisioning the infrastructure.
What are your experiences with handling large messages with the Kafka ecosystem? Did you or do you plan to use Apache Kafka and its ecosystem? What is your strategy? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.