Designing Enterprise Data Architecture on Salesforce.com

This article was originally published for DeveloperForce on November 5, 2014. See the following link: http://sforce.co/1tAKBEQ
Designing a good data architecture (DA) on Salesforce1 can often be the difference between a great success story or an epic failure. The DA of Salesforce affects almost ALL areas of your org – and therefore is not to be taken lightly or rushed into quickly. There are some key differences between Salesforce and other platforms that are critical to understand when designing your DA. Unfortunately most implementations do not have an enterprise perspective when they are being designed. This leads to significant refactoring as you increase your usage and knowledge of the platform.
First of all its important to understand the differences between Salesforce and other database applications.
- Salesforce looks and feels like a traditional OLTP relational database. However under the covers it has been architected very differently to support multi-tenancy, dynamic changes, and platform specific features. Do NOT assume data models move seamlessly from the old world into the new.
- Your data is co-located alongside other tenants. While this may cause security concerns, it will affect you more in terms of learning the scalability thresholds and governor limits that are placed upon the platform.
- Unlike traditional databases, Salesforce data cannot be dynamically joined through its query engine. Rather the “joins” are based on the predefined relationships between objects. Therefore the data model design is critical and understanding reporting requirements UP-FRONT is a key success factor.
- Salesforce is not a data warehouse (nor do they want to be). The recommended data strategy is to have the data you need and to remove the data you don’t. While that sounds like a pretty simple concept it is much more difficult to realize.
Let’s walk through the process of designing an Enterprise data architecture. An effective DA design will go through most if not all of the following steps:
Step 1 – Define Your Logical Data Model (LDM)
A good DA starts with a good logical design. This means you have taken the time to document your business’s description of the operations. You have a catalog of business entities and relationships that are meaningful and critical to the business. You should build your logical model with NO consideration for the underlining physical implementation. The purpose is to define your LDM that will guide you through your data design process. Make sure to take any industry relevant standards (HL7, Party Model, etc) into consideration.
Step 2 – Define Your Enterprise Data Strategy (including Master Data Management)
Outside the scope of this post (but totally necessary on an Enterprise implementation) is to define your enterprise data strategy. Salesforce should (theoretically) be a critical component but also subservient to your Enterprise Data Strategy. It will affect Salesforce DA in some of the following ways:
- Is there a Customer Master or Master Data Management system and if so what LDM entities are involved?
- What are the data retention requirements?
- How and when does the Enterprise Data Warehouse receive data?
- Is there an operational data store available for pushing or pulling real-time data to Salesforce?
Step 3 – Document the Data Lifecycle of Each Entity in the LDM
Each entity within the LDM will have its own lifecycle. It is critical to capture, document, and analyze each specific entity. Doing so will help you know later how to consolidate (or not) entities into objects, how to build a tiering strategy, and even how to build a governance model.
- Where is the source of truth for each entity? Will Salesforce be the System of Record or a consumer of it?
- How is data created, edited, and deleted? Will Salesforce be the only place for these actions? Will any of those actions happen outside Salesforce?
- What are they types of metrics and reporting required for this entity? Where do those metrics currently pull data from and where will they in the future state?
- Who “owns” the data from a business perspective? Who can tell you if the data is right or wrong? Who will steward the entity and ensure its quality?
- What business processes are initiated by this entity? Which are influenced?
- Get some estimates on data sizing for master entities and transactions. This will be very important when large data volumes (LDV) are involved.
Step 4 – Translate Entities and Cardinality into Objects and Relationships
Its time to start translating your LDM into a Physical Data Model (PDM). This is an art and not a science and I definitely recommend working closely with someone very knowledgeable on the Salesforce platform.
- Consolidate the Objects and Relationships were possible. Assess where it makes sense to collapse the entities, especially based upon common relationships to other objects.
- This is where record types become an important aspect of the Salesforce design. A common object can be bifurcated using record types, page layouts, and conditional logic design. A common architectural principle that I use is: “The More Generic You Can Make a Solution the More Flexible it Becomes”
- The tradeoff to consolidating objects is to consider the LOBs that will be using the object and your (forthcoming) tiering strategy. It may make sense to isolate an entity for technical, governance and/or change management reasons.
- Another downside to consolidating objects is the added need to partition your customizations. Be prepared to write different classes/web services/integrations at the logical entity level. For example, if 6 entities are overriding the Account object you will need custom logic for Business Customers vs Facility Locations vs Business Partners, etc – all hitting the Account object under the covers.
Step 5 – Determine whether to override Standard Objects
Another difficult decision becomes when to override a standard object vs building a custom object. Once again this is more an art than science but there are some key considerations along this topic:
- Why do you need the standard object functionality? Does Salesforce provide out of the box functionality that you would have to build your own if you go the custom object route? (e.g. Case Escalation Rules, Account Teams, Community Access, etc)
- Consider your license impacts between custom vs standard. Standard objects like Opportunity and Case are not available with a platform license.
- Don’t get carried away. Every “thing” in the world could be generalized to an account object while every “event” in the world could be generalized to a case. These types of implementations are very difficult to maintain.
Step 6 – Define Enterprise Object Classification and Tiering Strategy
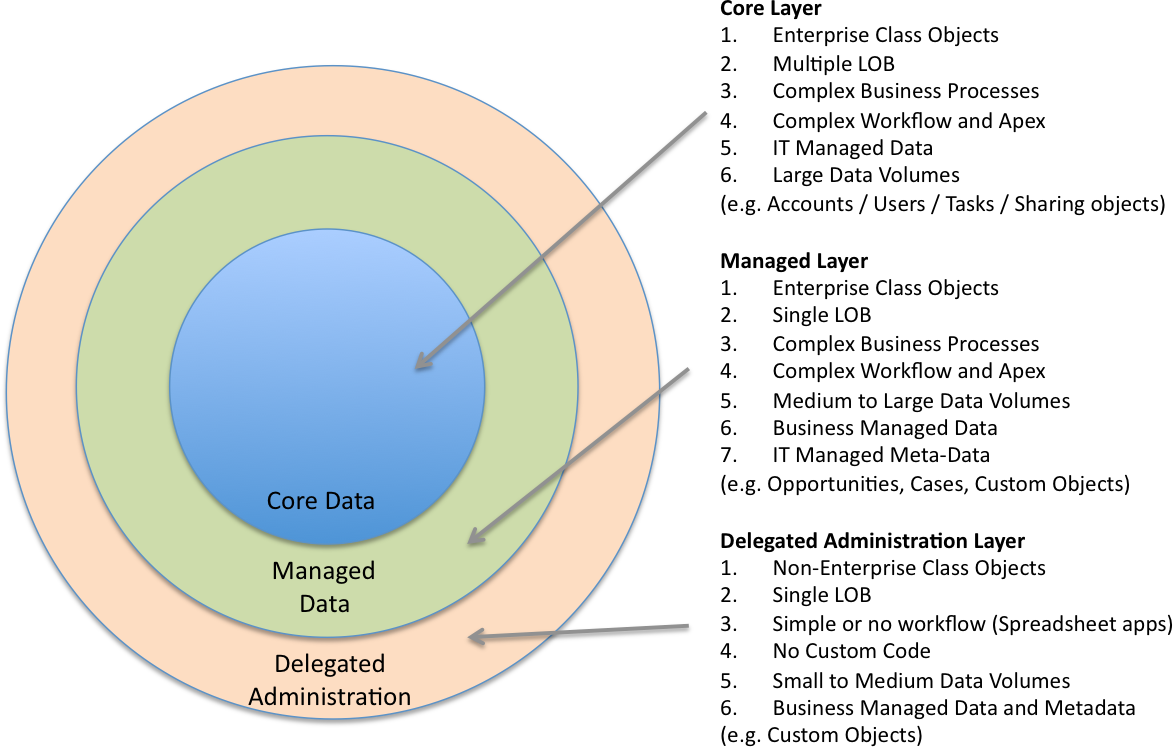
Object classification and tiering is an important component to an enterprise Salesforce DA. I try to classify objects across 3 different categories – however you may have more or less depending on your architecture design.
- Core Data – This is data that is central to the system and has has lots of complexity around workflow, apex, visualforce, integrations, reporting, etc. Changes to these objects must be made with extreme caution because they underpin your entire org. Typically these are shared across multiple lines of business (e.g. Account object), have LDV (e.g. Tasks), or complexity (e.g. Sharing objects). Information Technology should lock down the metadata and security on these objects pretty tightly. It will be up to IT to maintain the data in these objects.
- Managed Data – This is data that is core to a specific LOB but does not affect other areas of the system. Depending on the number of LOBs in the system this may or may not be something like the Opportunity or Case object. The objects still have high complexity in their workflow and customization requirements, however the object and code is regionalized to a single LOB. In this layer you can enable Business Administrators to manage the data for their LOB. In fact pushing data management of these objects into the business is critical to your ability to scale on the platform.
- Delegated Administration Data – These are typically custom objects that have been created for a specific LOB and are completely isolated from other areas of the system. They are typically “spreadsheet apps” or mini applications that have a very simple workflow and business processes. Therefore the data AND metadata of these objects should be put into the hands of business and delegated administrators. These objects become great candidates for Citizen Developers within the enterprise because you enable the business to make their own apps within a sophisticated environment.
You can also use your tiering strategy to assist with archiving (below). As you can move data out of the core layers and into delegated layers you will increase your scalability, agility, and even performance. Just make sure you are not creating data duplication and redundancy in your DA.
Step 7 – Design Your Security Model and Data Visibility Standards
Another architectural principal I recommend for Enterprise DA is “The Principle of Least Privilege“. This means that no profile should ever be given access to an application, object, or field unless specifically required. However I do NOT recommend making the entire sharing model private. This would cause significant and unnecessary complexity in your sharing design. Unnecessary private data will lead to data duplication issues and could also lead to performance impacts.
Step 8 – Design Your Physical Data Architecture
It is time to build a PDM. I call this “framing” as it will be the first time you can start to see what your solution will look like within Salesforce.
- Start to map out an object for each consolidated entity from your LDM.
- Which entities for your LDM are necessary to be persistent in Salesforce? Which entities can be kept off platform? Data that is not used to invoke business processes (workflow/triggers/etc) is a candidate to be kept off platform.
- Do NOT create objects for lookups where possible. Utilize picklists and multi-picklists as much as possible in an attempt to “flatten” your data model.
- Salesforce objects are more like large spreadsheets. There will be lots of columns and denormalized data in many cases vs a more traditionally normalized database.
- Take your earlier volume estimates for your LDM and reapply them to your consolidated design. You should have a rough order of magnitude now for each consolidated entity you are considering. Try to get specific volumes at this point. It becomes very important for licensing and LDV.
- Make sure you have considered many-to-many relationships as these “junction objects” have the capability to grow very large in Enterprise environments.
- Any objects with volumes in the millions should be considered for LDV impact. While outside the scope of this post you may want to consider changes to your PDM to minimize volumes where possible.
- Data replication and duplication in Salesforce is OK. (Data architects please sit back down.) Sometimes it is necessary to support the business processes utilizing these frowned upon methods. Salesforce actually works best when you break some of the traditional rules of enterprise data architecture – especially normalization.
As far as data off platform is concerned… I recommend keeping data off platform that you don’t need. You want Salesforce to be a corvette in your enterprise (fast, agile, sexy) vs a utility van (slow, unkept, and kind of creepy).
Step 9 – Define Enterprise-wide and Org-Wide Data Standards
It is time to build a set of standards when it comes to your data model. You need to consider Field Labels vs API names, and common fields to maintain on each object. Also coming up with an enterprise model for your Record Types will be critical.
The following list is what I like to do:
- I create Record Types on EVERY object. The first record type usually has a generic name like <Company Name>. (e.g. Dell, IBM, Google, etc). It is much easier to refactor objects in the future if you start with record types from the beginning.
- LOB specific Record Types always begin with a LOB designator (e.g. CC – Incident for “Contact Center”)
- LOB specific objects and fields should have the LOB designator in the API name. (e.g. CC_Object__c, CC_Field_Name__c)
- Depending on the number of fields you expect to have on a given object, consider tokenizing the API name (e.g. CC_FldNm__c). This will greatly save you later when you are hitting limits on the number of characters that can be submitted in SOQL queries.
- I create common fields on EVERY object. Fields like “Label” and “Hyperlink” can hold business friendly names and URLs that are easily used on related lists, reports, and email templates.
- I usually copy the ID field to a custom field using workflow or triggers. This will greatly assist you later when trying to integrate your full copy sandbox data with other systems. (I never use the Salesforce ID for integration if it can be avoided).
You may or may not want to follow these. The point is create your standards, implement that way from the beginning, and govern your implementation to ensure your standards are followed.
Step 10 – Define Your Archive & Retention Strategy
Even though Salesforce has a great history and reputation for keeping your data safe, you still have a responsibility to your organization to replicate and archive the data out of Salesforce. Here are some considerations:
- It is more likely that you will break your own Salesforce data than for them to suffer a data loss. Salesforce will assist you should you need to try to recover your data to an earlier state, but a mature enterprise needs to have the capability to be self-sufficient in this area.
- Weekly backups are provided from Salesforce and maybe fine for SMB, however I recommend a nightly replicated copy. There are partner solutions that will make this easy – or you can build a custom solution using the Salesforce APIs.
- I would use your replicated copy for 2 purposes. One would be to feed your data warehouse as necessary. The other is for recovery purposes. I would NOT use the replicated copy for reporting and I would try to not use the replicated copy for any real time integration requirements. This adds an undue burden to your technical environment and ties your Cloud solution into your on-premise infrastructure. Tightly coupling Salesforce to your existing IT infrastructure may cripple your agility and flexibility in the cloud.
Step 11 – Define Your Reporting Strategy
Your architecture is defined. You know what data will be on platform, what data will be off-platform, and where the best sources of all of this data is. Its time to define a reporting strategy for your Salesforce data. Your strategy will be different depending upon your data architecture – but I will suggest the following guidelines that I have used successfully in large enterprises.
- Operational Reporting should be done on Platform if possible. The data necessary to support a business process will hopefully be on platform long enough to run your operational reports.
- Analytical Reporting should be done off Platform. Use traditional BI tools built upon your data warehouse for long running, trending, and complex reports.
- Use the out of the box reporting and dashboards as much as possible. Try to get your executives and stakeholders the reports they need coming directly from Salesforce.
- Consider mashup strategies for off platform reporting solutions. Some third parties offer applications that will integrate seamlessly into the Salesforce UI so users never need to leave the application.
- Consider building custom reports using Visual force or Canvas where appropriate. The more you keep your users in the platform the more influence and momentum you will maintain. As users move to other tools for reports, so too will their interest, attention, and eventually funding.
- Don’t report out of your replicated Salesforce database. Move that data into the data warehouse if analytical data is needed and keep users in Salesforce for real-time data. Offline Salesforce reports will just confuse users and cause undue issues regarding data latency and quality.
Step 12 – Repeat
Just like Enterprise Architecture, defining your Data Architecture is iterative and will continually improve. Each time you go though an iteration you will increase in your understanding, maturing, and competency on the platform. And as you improve your data architecture, so too will the business value of your Salesforce deployment increase.
Other Helpful Resources
Salesforce’s Best Practices for Large Data Volumes











Pingback: Building an Enterprise Architecture with Salesforce.com | The Enterprise Force.com Architect
Pingback: Managing Complexity in your Enterprise Salesforce1 Implementations | The Enterprise Force.com Architect
Hey Greg, thanks for sharing this, I found this article extremely helpful and kind of mind blower. Are you still writing articles somewhere else or some Architect you know sharing real word Enterprise experiences/pattersn like this ones? I’d love to know more about DX used on Org centric projects. I been frustrated when I tried to use it couple of months ago..
Also have some concerns when developing automations around triggers, PBs AND Workflows. Like not able to follow Enterprise Patterns and modularize, good practices are a bit contradictory at some points when you try to switch to DX on Org centrics…
Thanks again!